
Stell dir vor, du könntest mit ChatGPT oder mit Gemini auf deine eigenen Daten zugreifen. Du findest deine relevanten Dokumente und Passagen in Sekundenschnelle, sie werden dir als Links angezeigt und automatisch zusammengefasst.
Dies ist möglich mit RAG (Retrieval Augmented Generation). Mit der RAG-Methode wird zuerst ein Dokumentenkorpus durchsucht, um relevante Dokumente oder Textstellen zu finden, die zur Beantwortung einer Suchanfrage nützlich sein könnten. Anschliessend wird ein Sprachmodell verwendet, um auf Basis der vorher identifizierten Dokumente eine kontextbezogene Antwort zu erzeugen. RAG wird beispielsweise im kostenpflichtigen Microsoft Copilot verwendet. Mit gemischtem Erfolg, wie zum Beispiel c’t in einem Test (2024 im Heft 8) zeigt. Ein Zitat aus deren Fazit: «Im derzeitigen Zustand ist der von Microsoft als einsatzbereiter KI-Assistent vermarktete Office-Copilot bestenfalls eine Technik-Demo. Man kann aber auch von einem öffentlichen Betatest reden, den die Tester bezahlen, also die Abonnenten von Copilot Pro und Copilot für Microsoft 365». Nebenbei für alle, die von den Produktenamen von Microsoft ebenso verwirrt sind wie ich: «Copilot Pro» ist der KI-Assistent für Private Abonnenten und «Copilot für Micorsoft 365» ist der KI-Assistent für jene, die Unternehmens- und Schullizenzen haben.
Stell Dir nun vor, Du hast einen unstrukturierten Dokumentenhaufen aus Word-Dokumenten, Excels, Bildern, PDFs etc. Und Du möchtest richtig gute statt nur durchschnittliche Suchresultate erzielen.
Der Häcksler macht bei Suchbots den Qualitätsunterschied
RAG-Lösungen sind heute relativ einfach umzusetzen. Unsere Erfahrung in diversen Projekten mit semantischer Suche und Chatbots hat jedoch gezeigt, dass die hohe Kunst nicht RAG ist. Es ist das Handwerk, das RAG vorgelagert ist. Denn nicht das eigentliche Durchsuchen und Vektorisieren der Daten ist schwierig, sondern das vorgelagerte Strukturieren des Dokumentenberges, den es zu durchsuchen gilt. Um sehr gute Suchresultate zu erzielen, braucht es das, was wir von poemAI einen Super-Häcksler nennen. Beim Häckseln geht es darum, aus Dokumenten semantisch kohärente Textpassagen zu extrahieren, die dann der KI zugeführt werden. Wird der Text in zu kleine oder zu grosse Passagen zerlegt, nimmt die Wahrscheinlichkeit ab, bei der Suche die besten Textpassagen zu finden. Weil die vektorisierte Textpassage zu wenige Informationen enthält oder zu viele irrelevante Informationen. Warum, das könnt ihr im Blog «Semantische Suche einfach erklärt» von Markus Emmenegger nachlesen.
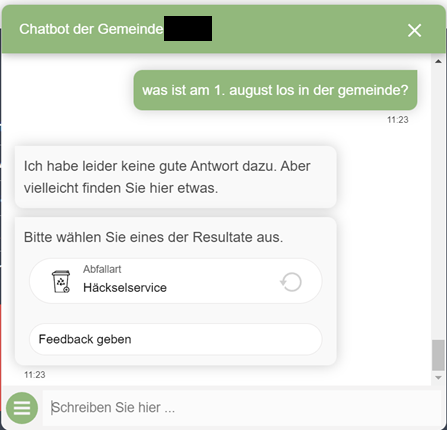
Bei durchschnittlich performenden Such- und Chatbots werden Texte in der Regel einfach zufällig zerschnitten (wenn überhaupt). Zum Beispiel wird eine A4-Seite in vier gleich grosse Teile zerhackt. Dies führt schlussendlich zu den fragwürdigen Suchergebnissen, wie wir sie im Web häufig finden. Hier ein Beispiel eines Chatbots einer Schweizer Gemeinde, der Qualität offenbar weniger am Herzen liegt als uns. Man wünscht sich, diese Gemeinde hätte bessere Embeddings verwendet und den Häckselservice von poemAI in Anspruch genommen.
Was einen guten Häcksler ausmacht
Die Aufgabe, einen Text in sinnvolle Abschnitte zu zerteilen, scheint auf den ersten Blick einfach. Man könnte zum Beispiel damit anfangen, den Text in seine einzelnen Sätze zu zerlegen – also einfach bei Punkten zerlegen. Dass das gar nicht so einfach ist, zeigt folgende Textpassage: «Dr. med. dent. Klaus Muster ist seit dem 22. November 1985 in Zürich, Bern etc. tätig. Er bespricht die neuesten Trends in der Zahnmedizin auf seiner Website, besuche ihn unter meineseite.ch. Seine Forschungen haben große Anerkennung in der Fachwelt gefunden.» Natürlich gibt es Funktionen in Sprach-Tool-Bibliotheken (z.B. NLTK), die den Abschlusspunkt erkennen können. Wie so häufig erschöpft sich deren Können aber in Englisch. Die Ergebnisse deutscher Adaptionen sind jenseits unseres Qualitätsstandards.
Noch schwieriger wird es, wenn man einen langen Text in zusammenhängende Abschnitte teilen will – was für RAG zentral ist. Das sogenannte Text Tiling ist ein Jahrzehnte altes Problem. Ein allgemein akzeptiertes, mehrsprachenfähiges Standardtool, welches auf den unterschiedlichsten Textarten funktioniert - und das auch noch in Deutsch - haben wir nicht gefunden. Bezüglich dieser Frage gibt es offenbar keinen Wettbewerb wie zum Beispiel bei den Sprachmodellen. Es gibt nur vielversprechende Ansätze, Ideen und Papers.
Also haben wir im Laufe des letzten Jahres unseren eigenen Super-Häcksler entwickelt. Er kann der Texte zuverlässig in seine semantisch kohärenten Abschnitte zerlegen. Natürlich mit KI. Entsprechend sind die Suchergebnisse in unseren Suchbots überragend.

Häckseln und RAG funktionieren auch im Hochsicherheitstrakt
Stell dir vor, du kannst bedenkenlos mit KI auf Dokumente zugreifen, die sensibel und schützenswert sind und nicht in Sichtweite von OpenAI, Microsoft oder sonstigen Dritten gelangen dürfen.
Die oben beschriebenen RAG-Technologie inklusive vorgelagertem Häckselservice kann man auch in geschützten Umgebungen nutzen. Nur dass in diesen Fällen alles im Hochsicherheitstrakt passiert. Der Häcksler wird auf einem lokalen Server laufen gelassen. Und für das Embedding, die semantische Suche und das Erstellen des Antworttextes wird ein lokales Sprachmodell verwendet. Was es dabei zu bedenken gilt, habe ich in meinem Blog «KI und Datenschutz» beschrieben. Markus hat die technischen Lösungen hierzu in seinen letzten beiden Blogs beschrieben: Heikle Daten im Browser verarbeiten und wie man schlanke Bots baut.